
Google I/O 2026: The Rise of Frictionless Software
Google I/O 2026 marked the end of “prompt-and-response” and the start of “delegate-and-execute.” In this deep dive, you’ll unpack the four themes that defined the keynote. You’ll review the infrastructure powering safe autonomous agents (Gemini 3.5 Flash, Spark, and Antigravity 2.0), AI that generates user interfaces on the fly, the new “vibe coding” development pipeline, and the push into ambient, spatial computing and what it all means for developers when the baseline execution layer becomes automated. By Zac Lippard.
For most of the last decade, “using software” meant the same thing it always had: you opened an app, you did the work, and the app sat there politely waiting for your next click. Even the first wave of generative AI didn’t really change that pattern. You typed a prompt, you got a response, and then you, the human, went off and did something with it. The machine was a very smart vending machine. You put a question in, an answer came out, and the actual work still landed on your desk.
Google I/O 2026 was the moment that contract quietly expired.
This year’s keynote wasn’t a parade of chatbots. It was a demonstration of workers: software that takes a goal, disappears for a while, and comes back with the task done. The throughline across nearly every announcement, from the data center to the smart glasses, was a single shift in posture: from Prompt-and-Response to Delegate-and-Execute. You’re watching software evolve through distinct stages. From software you use, to software that works for you, to environments that adapt to you.
In this article, you’ll dig into the four themes that defined I/O 2026 and, more importantly, why each one matters to you as a developer:
- The infrastructure that finally makes autonomous agents safe and fast enough to trust.
- The death of the static layout, as AI generates user interfaces on the fly.
- The new development pipeline, where you direct architectural intent instead of typing syntax.
- The expansion of computing off the glass screen and into ambient, spatial environments.
This isn’t a feature checklist. It’s a look at what happens when the baseline execution layer of software becomes automated and what that leaves for you to do.
Theme 1: The Invisible Worker
The dirty secret of “AI agents” up to this point is that they mostly didn’t work. Not because the models were dumb, but because the infrastructure around them was hostile to autonomy. Agents were too slow to chain dozens of steps without testing your patience, too dangerous to let near a real terminal, and too tied to your local machine to do anything while you closed the lid and went to lunch. I/O 2026’s first big theme was Google quietly solving all three problems at once.
The Baseline Engine: Gemini 3.5 Flash

The headline model wasn’t the biggest one, but it was the fastest. Google bypassed the usual slow, staged rollout and pushed Gemini 3.5 Flash straight into production across its products. The reasoning becomes obvious the moment you stop thinking about Flash as a chatbot and start thinking about it as an engine for agents.
The benchmarks tell the story. Flash posted a massive leap of 76.2% on Terminal-Bench 2.1, the suite that measures how reliably a model can operate a real command line across multi-step tasks. It also had an 83.6% increase on MCP Atlas, which evaluates how well a model orchestrates external tools through the Model Context Protocol. Those two benchmarks aren’t about trivia or essay-writing. They measure whether a model can act: run a command, read the output, decide what to do next, and not fall apart halfway through. For a deeper dive into the benchmarks see Google’s blogpost on Gemini 3.5.
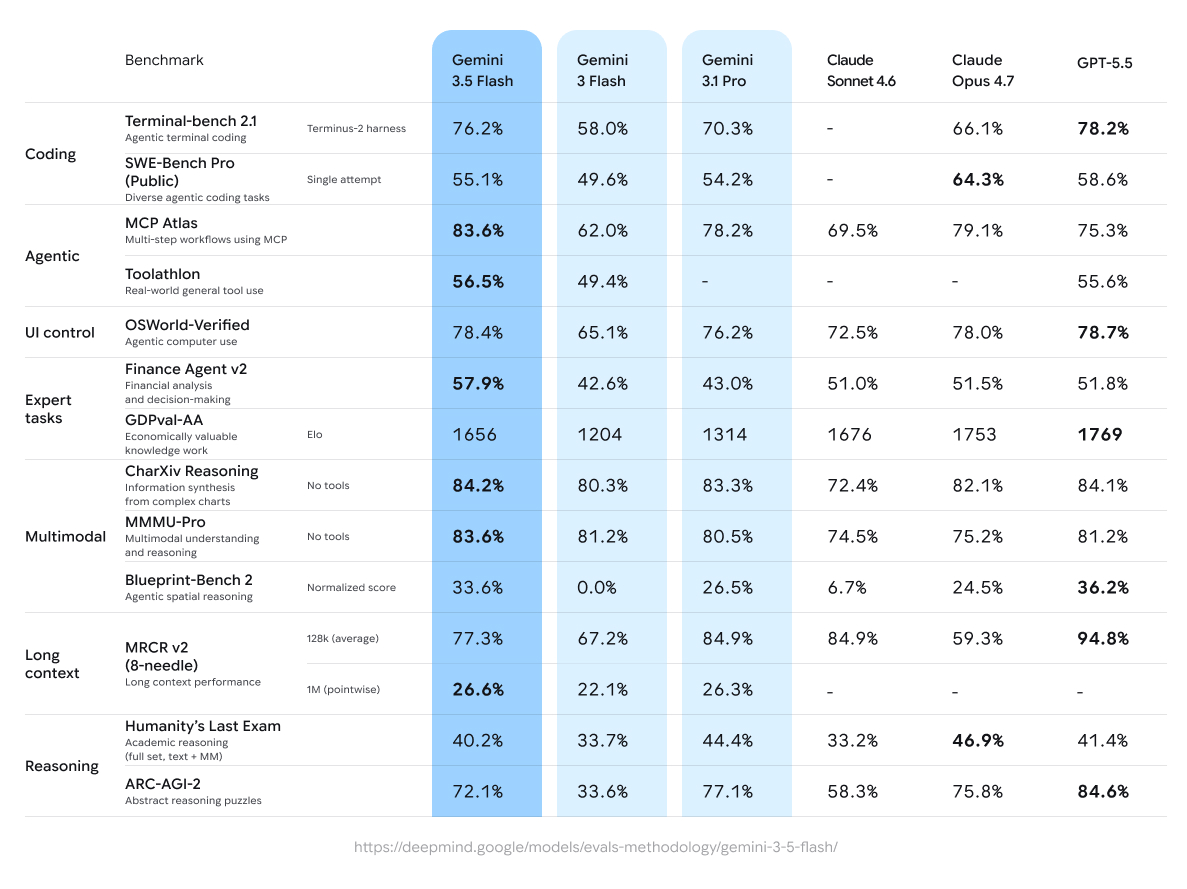
But the number that actually matters is speed. Flash runs roughly 4× faster than the previous generation of frontier models. That sounds like a quality-of-life improvement until you do the math on an agent. A single agentic task might involve fifty model calls like read a file, plan, call a tool, evaluate the result, re-plan, and so on. At frontier-model latency, fifty sequential calls is a coffee break. At Flash’s latency, it’s a few seconds. Speed isn’t a luxury here; it’s the prerequisite that makes multi-step autonomy tolerable. You can’t delegate a twenty-step job to something that makes you wait twenty times.
The Always-On Virtual Machine: Gemini Spark
If Flash is the engine, Gemini Spark is the garage it runs in. Spark reframes what “running an agent” even means. Today, when you kick off an AI task in your browser, it runs in the context of that tab. Close the laptop and the work dies with it. Spark breaks that dependency entirely.
Instead of executing client-side, Spark provisions dedicated, isolated virtual machines on Google Cloud for each task. Your agent doesn’t live in your browser tab. It lives on a real machine in a data center, with its own filesystem, its own network access, and its own lifecycle. The practical consequence is background execution of long-horizon tasks: jobs that take minutes or hours and involve many steps.
Picture handing off a request like “go through these 400 invoices, flag the ones that don’t match the contract terms, and draft the dispute emails.” That’s deep file triage and a chain of API calls, exactly the kind of work that’s too tedious to babysit. With Spark, you dispatch it and walk away. The machine grinds through the task in the background while your laptop lid is closed, and you come back to a finished result. The mental model shifts from “I’m running a tool” to “I’m managing a coworker who has their own desk.”
The Security Layer: Antigravity 2.0 & Linux Sandboxing
Now for the elephant in the room, and the part written specifically for engineers: an agent that can run terminal commands is an agent that can drop your database, leak your API keys, or force-push over main. Autonomy without isolation isn’t a feature; it’s an incident report waiting to happen. This is where Antigravity 2.0 comes in.
Antigravity 2.0 is a standalone desktop engine that gives agents isolated Linux sandbox environments to work in. Instead of executing against your real machine and real credentials, the agent operates inside a contained box with three critical guardrails:
- Isolated sandboxes: file and process operations happen in a disposable Linux environment, so a destructive command nukes the sandbox, not your system.
- Strict Git policies: the agent can branch and commit, but force-pushes, history rewrites, and pushes to protected branches are blocked by policy rather than by hope.
- Credential masking: secrets and API tokens are injected at the moment of use and masked from the model’s context, so an agent can authenticate to a service without ever “seeing”, or accidentally logging, the token.
Conceptually, the policy layer is a declarative set of rules that fences in what the agent is allowed to touch:
sandbox:
runtime: linux-isolated
network: allowlist-only
filesystem: ephemeral
git:
allow: [branch, commit, pull]
deny: [push --force, rebase, push:main]
secrets:
inject: runtime
mask_from_model: true
The point isn’t the exact syntax but rather the philosophy. Antigravity 2.0 treats the agent as an untrusted execution context by default, the same way a well-designed CI pipeline treats arbitrary build scripts. Once you can guarantee that an agent physically cannot exfiltrate a credential or rewrite history, you can finally let it run terminal code without sweating. Security stopped being the thing that prevented agentic coding and became the thing that enables it.
If you want to give Google Antigravity a whirl, check out https://antigravity.google/.